On-Brand AI Documents, Across Every Model
An AI assistant was generating client documents that drifted in fonts, colours and layout from one model to the next — and sometimes invented a brand outright. We turned its instruction files into a measurable, optimised system and cut inconsistency 76%.
76% reduction in cross-model branding inconsistency; invented-brand and shadow failures eliminated; one palette and one font system across every model
The Problem
A wealth-advisory practice let its AI assistant generate client deliverables — one-pagers, reports, notes — from a folder of plain-language "skill files." In practice the output drifted: the same request produced different fonts, colours, and heading sizes depending on which model answered or how the request was phrased. Worse, when the assistant failed to load the right brand instructions, it invented a firm name and a palette of its own.
There was no way to know how bad it was, or whether any given edit actually made it better. "Looks right to me" is not a system.
The Approach
We treated the assistant's instruction files as the thing to optimise — and measured the result like an experiment.
- An isolated test harness. Each test runs the assistant in a clean sandbox, stripped of the operator's own settings, so results reflect the instruction files themselves and not the developer's machine. A fixed battery of document requests — phrased the way a real user would — runs across multiple model tiers, each producing a real document.
- A consistency metric. Every document is parsed into a style fingerprint: fonts, colour palette, font-size per role (title, heading, label, body, footer), layout clutter, and whether the correct brand skill was even loaded. A single score sums weighted penalties; lower is better. It rewards the same element looking the same everywhere — across documents and across models.
- An optimisation loop. One agent edits the instruction files while the metric scores the result, keeping a change only if the score improves and reverting otherwise. Each candidate is evaluated three times and scored on the median, because model output is stochastic — and every accepted step is a reviewable commit.
The Result
The decisive gain came from one structural change: collapsing several overlapping instruction files into a single source of truth that every document skill must cite. The autonomous loop then confirmed there were no easy further gains, correctly rejecting noisy candidates rather than overfitting to a lucky draw.
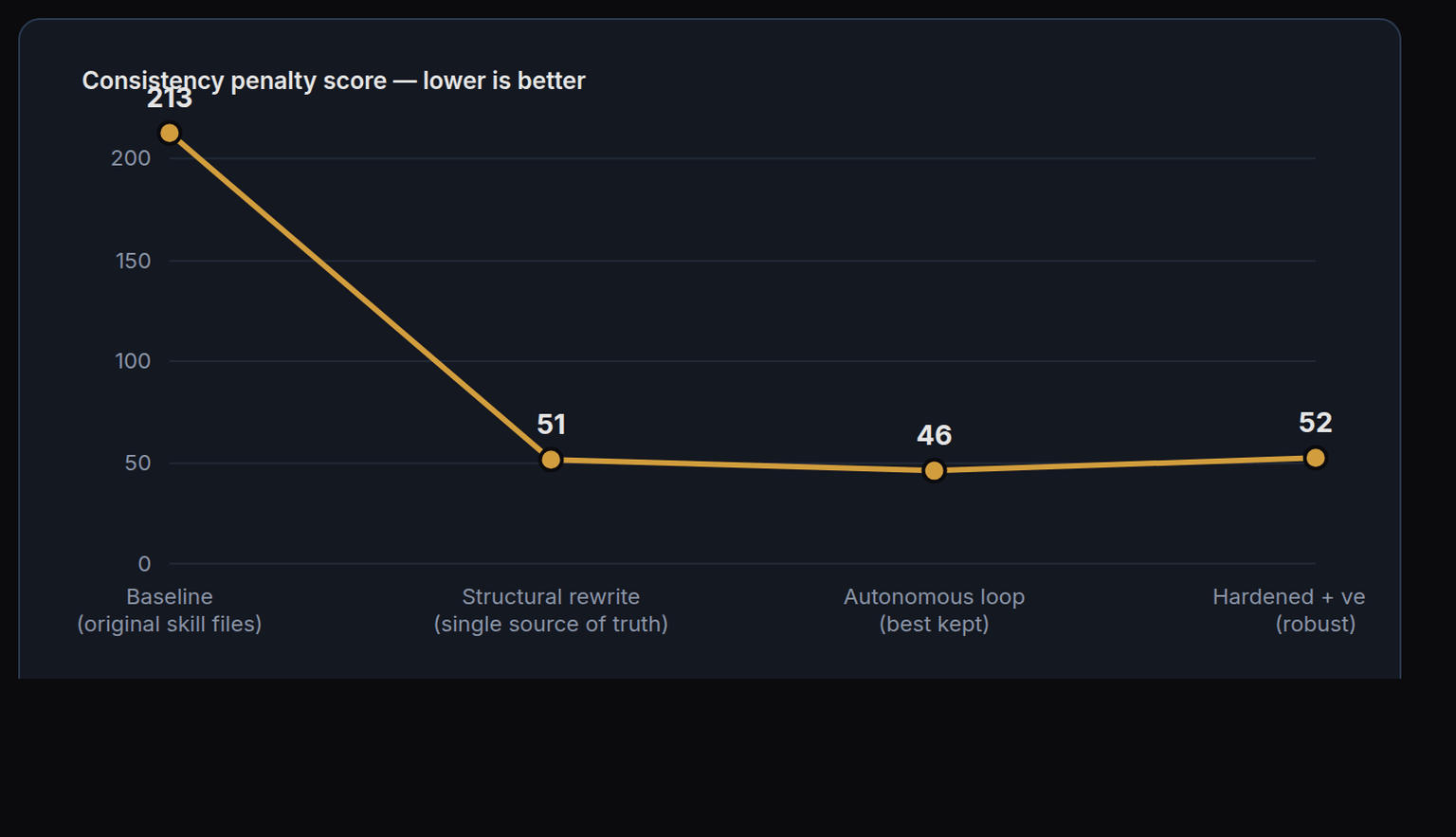
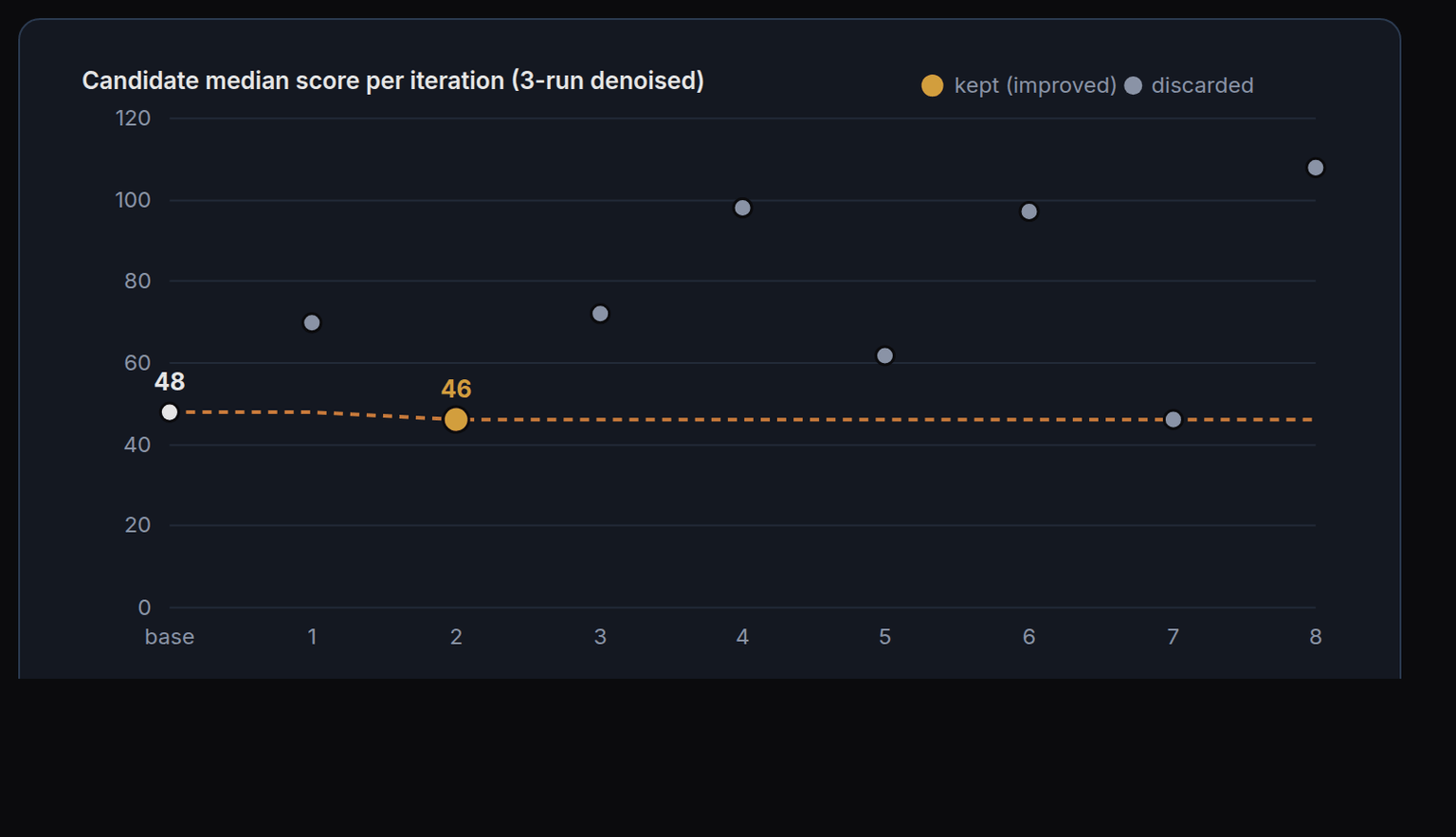
Skill discovery went from roughly half of runs to every run; five competing palettes became one; four font systems became one; and shadow artefacts and invented brands disappeared. The variance that remains is the model's own run-to-run randomness — a floor that instructions cannot cross — so the system is tuned to hold the worst case, not just the average.
Key Metrics
- Inconsistency score: 213 → ~50 (−76%)
- Correct-skill discovery: ~5 / 9 → 6 / 6 runs
- Palettes / font systems: 5 / 4 → 1 / 1
- Invented brands & shadow artefacts: present → none
- Build: isolated harness + optimisation loop, ~1 day
Services
Interested in similar results?
Start a Conversation